Improving Rewards Claim Success


Motivation
In 2022, Audius launched a decentralized rewards system built on Solana to incentivize top of funnel activity by providing users small amounts of $AUDIO in-app for activity. For example, whenever an artist earns 1 USDC from a sale on the Audius network, both the fan and artist earn 1 $AUDIO matched to their purchase/sale. To learn more about that system, see this blog post: https://engineering.audius.co/direct-messaging-on-the-audius-client.
Claiming $AUDIO rewards on Audius historically has had an absolutely abysmal success rate, even after several improvements over the years. Though users are often able to make a successful claim on subsequent retry attempts, the user experience is severely lacking. What was causing attempts to claim rewards to fail in the first place?
Diagnosis
We exported data from Amplitude, our user behavior analytics tool, and got 1452 errors to play with. Our error reporting has been changing and so we had do some manual grouping, but this is what the data looked like:
| Error | Count | Percentage of all Errors |
|---|---|---|
| Transaction Expired | 568 | 39% |
| Not enough signer keys | 356 | 25% |
| Blockhash Not Found | 137 | 9% |
| Repeated sender | 75 | 5% |
These four errors accounted for 78% of all errors! What was happening here?
Solana Errors: "Transaction Expired" and "Blockhash Not Found"
Both of these errors are general Solana errors and deal with the blockhash used in a submitted transaction.
Transaction Expired Blockheight Exceeded
"TransactionExpiredBlockheightExceededError" happens when a transaction isn't processed, confirmed, and finalized into Solana's network before the blockhash included in that transaction is older than the last 151 most recent blockhashes. In practice, it functions as effectively a timeout. When Solana was experiencing large amounts of network congestion, we would see a large amount of these because the sent transaction didn't make it to the validator at all. However this problem was solved at the infrastructure level of RPCs and shouldn't be an issue today. The way this "timeout" works is that the transaction is only valid and will only succeed while the blockhash included in the transaction is within the last 151 blockhashes, so once the block height moves far enough (ie we no longer have to keep watching and waiting for confirmation, and can safely assume the transaction will fail if it does get processed any later by a validator.
Spot checking a few of these, we noticed that while we return this error, a lot of the failed transactions do actually make it through, which means there's something weird going on here with the confirmTransaction call that claims that it expired. This shouldn't happen - the whole point of that recent blockhash expiry strategy is to prevent this from being possible!
The solve here was to switch RPC providers. The RPC provider we were using didn't support websockets, which is what the confirmTransaction call relies on internally in @solana/web3.js. Our code would continually poll the getLatestBlockhash and eventually get past the lastValidBlockHeight and never get the onSignatureStatus change event for the transaction, despite the transaction being confirmed. This didn't solve all expiring transaction errors but it made a huge dent.
Blockhash Not Found
"Blockhash not found" occurs when the blockhash included in a transaction isn't found yet on the RPC provider. These errors typically happen upon simulation, which our relay only does against a single node. Since our RPC provider on the relay side doesn't match the RPC used on the frontend to fetch the latest blockhash, the relay-side RPC provider can be behind the frontend RPC provider. In that case, the one used for simulation on relay doesn't know about the blockhash used in the transaction as it hasn't seen it yet, and errors with "BlockhashNotFound."
There's a couple of different solves for this. We can:
- Sync the front and backend RPC providers to be the same.
- Skip preflight (simulation) checks.
- Use a less stringent commitment on the relay side vs the frontend (eg. use "processed" preflight commitment when simulating, but "confirmed" when fetching the latest blockhash) to increase the odds of that blockhash being indexed.
- Retry the simulation on relay side for a bit if we see "blockhash not found."
- Replace the blockhash before simulation with a blockhash that the RPC on the relay-side does know about. (Just for simulation! Don't want to break the existing signatures if there are any).
Luckily, there's built-in support for #5: when calling simulateTransaction , there's an optional replaceRecentBlockhash parameter that will tell the RPC node to replace the simulated transaction's blockhash with one that will be valid. Doing this eliminated this class of simulation failures immediately!
Reward Manager Errors: "Not Enough Signer Keys" and "Repeated Sender"
The other two of these errors are from our Reward Manager program.
The Reward Manager program on Solana is the gatekeeper for rewards claiming, and it only disburses rewards if three independently operated Discovery Node services and one Anti Abuse Oracle service attest to a user having performed the necessary action to deserve a reward. These attestations are codified as Secp256k1 signatures generated from the node's private key. The nodes creating these attestations are called "senders" and "signers" interchangeably in the program. So when the program returns "Not enough signer keys", that means there weren't enough node attestations to disburse the reward. When the program returns "Repeated Sender", that means the given node has already submitted an attestation.
The reason these errors are even possible is because of the way the Reward Manager is architected. It should be noted that the Reward Manager program predates a lot of the features and tooling that have come to Solana. One of the biggest hurdles we had to overcome in the initial implementation was the transaction size limit of 1232 bytes. To do it, we had to split apart the submission of attestations into multiple transactions, and store the attestations in a program derived account (PDA) until finally submitting an "EvaluateAttestations" instruction to check that account, verify the attestations are all there, and disburse the reward.
There's an interesting quirk in our program code that further complicates this: If an extra attestation is submitted beyond the necessary min_votes + 1 (min_votes is 3 on mainnet for three discovery node attestations and one anti abuse attestation), the attestations account is cleared completely to prevent deadlocks and allow for retries. This burned us in the first implementation of reward claiming on the client, as we didn't account for any previously submitted attestations and would try to submit all four of them every attempt. If one transaction failed, but the other submission transactions succeeded, you would end up in a state where you would never be able to claim your reward, because each time your count would go past 4 and the account would be cleared!
The next client implementation tries to be smarter. It checks the account that's holding the submitted attestations, learns what's missing, and only fetches and submits the missing attestations before attempting to disburse. So why are we still getting these errors?
Hypothesis: RPC state de-sync
When our relay sends the four transactions required, it may be using different RPC providers on each transaction. Those RPC providers might be at a different height of their chain state than the client and failing to see the recently submitted attestations when they run the simulation. (Note: Even if we did use the same RPC provider, internally some RPC providers may use a load balancer among a fleet of nodes that aren't in sync with each other!) We attempted to solve for this by skipping the preflight simulation checks, but the problem persisted.
Our next guess was the frontend RPC provider we were using was fetching the wrong state for the submitted attestations, and again submitting too many attestations and causing the attestations account to clear. We were definitely seeing the symptoms - some of the repros we caught ourselves would have a cleared account state after a failure - so we set on solving this.
Claiming rewards in a single transaction
The landscape has changed
There's a lot we would change about the Reward Manager program in another iteration. It's far too overly complex for what it's doing, and can be greatly simplified with help from the newest tooling and features, like Anchor and better cross program invocation support. We could save so much space in the transactions by not repeating same data so many times. For instance, sending multiple Secp256k1 signatures but the data being signed only once, and using CPIs to Secp256k1 program to verify the signatures instead of repeatedly sending the data.
So many of these bugs for this flow seem to come from having so many transactions for each claim. If you have 10 rewards to claim, and attempt to claim them all, you'd be sending 40 HTTP requests to the nodes, and 50 transactions! (Note: our initial iteration tried to be smart and group some attestation submissions instructions together, but in the end it actually added too much complexity and masked errors).
Unfortunately, it's too much for us to invest right now in a full rewrite in something like Anchor, and go through the overhead of a new audit and additional testing. But maybe there's something that can work right now that can help us at least squeeze these instructions into one single transaction, without any program level changes?
Address Lookup Tables and Versioned Transactions
The Reward Manager program predates versioned transactions and their address lookup tables, so this wasn't an option at its inception. But lucky for us, it is now! And unlike rewriting in Anchor or switching to CPIs for the Secp256k1 signatures and other ideas, this one doesn't require any program level changes. Maybe, just maybe, if we put all the addresses we can from these instructions into a lookup table, we can save just enough space to fit all the instructions in one transaction, and avoid the RPC sync problem altogether.
Anatomy of a full disbursement transaction
A complete transaction for claiming a reward needs at least 9 total instructions, as attestation submissions are paired with Secp256k1 instructions:
- An Secp256k1 instruction with the signature from anti abuse oracle
- A Submit Attestation instruction for the anti abuse oracle
- An Secp256k1 instruction with the signature from the first discovery node
- A Submit Attestation instruction for the first discovery node
- An Secp256k1 instruction with the signature from the second discovery node
- A Submit Attestation instruction for the second discovery node
- An Secp256k1 instruction with the signature from the third discovery node
- A Submit Attestation instruction for the third discovery node
- The Evaluate Attestations instruction to disburse
There's a lot of accounts that are required for this to work, but some of them are static and can be put in the lookup table:
- System Program ID
- SYSVAR_RENT_PUBKEY
- SYSVAR_INSTRUCTIONS_PUBKEY
- TOKEN_PROGRAM_ID
- The rewardManagerState address (where the configuration is stored for this "instantiation" of the reward manager)
- The rewardManagerAuthority address (the owner of the token account)
- The rewardManagerTokenSource address (the token account with the $wAUDIO to reward with)
Additionally, the Lookup Table can be maintained to have every possible sender account, the derived Solana accounts for the Discovery Nodes and Anti Abuse Oracles, so all of those are added as well. Maintenance of this might be manual and annoying at first, but it can be automated in the future should nodes be added more frequently.
Doing this, we managed to get the transaction size down to just below 1232, at 1212 bytes in the initial test. However, it was clear we wouldn't be able to fit any ComputeBudget instructions. We decided this was a valuable tradeoff for us, as success was so low and we estimated that losing priority fees but getting everything into a single transaction would still increase success.
Devastating news
When implementing and testing this single-transaction solution, we stumbled upon bad news: Despite the generous 20 bytes of headroom in the transaction, somehow one of the test transactions was too large by 5 bytes.

What was the difference?
In the initial (successful) test, we looked at the "$AUDIO Match (Buyer)" reward that users get for purchasing a track on Audius. In the failed test above, it was the "Track Upload" challenge that users get for uploading three tracks to Audius. These challenges have different IDs and each claim has a different specifier that's used to distinguish it from other claims.
- An "$AUDIO Match (Buyer)" challenge has the ID
b, and as it can be claimed once per content per user, the specifier includes both the content ID and user ID in a string in the form${buyerUserId}=>${contentId}, where${buyerUserId}is the user's numeric ID and${contentId}is the track or album numeric ID (eg.123456=>456789) - The "Track Upload" challenge has the id
track-upload, and as it can be claimed once per user, the specifier is the user's numeric ID
The challenge ID and specifier are used as seeds to derive a "disbursement account" for the program, and that disbursement account is used to mark when a reward has already been claimed. This protects against repeat claims against a reward before the nodes index the initial claim disbursement and stop attesting to it. The "disbursement ID" is in the form ${challengeId}:${specifier} so for instance b:123456=>456789 or track-upload:123456 . Since this is being used as a seed to the derived account, it needs to be less than 32 bytes, which is the main reason b was chosen for the ID for the "$AUDIO Match (Buyer)" challenge rather than a longer identifier.
In the initial successful test of the single transaction method, we naively assumed that since we have an extra 20 bytes of headroom on the transaction, and the disbursement ID was more than 12 bytes, we would have enough room for even the largest disbursement ID. But the disbursement ID isn't only included in the evaluate instruction. It's also part of the payload that the Discovery Nodes and Anti Abuse Oracles are signing as part of their attestations. It's included as instruction data in each Secp256k1 instruction as well as its paired Submit Attestation instruction. That means this disbursement ID is repeated NINE TIMES in the single transaction - once per each instruction. Our first test had gotten even more lucky than we thought - each additional byte of the disbursement ID brings the transaction size up by nine bytes, so that first successful transaction's disbursement ID was only 3 bytes away from failure!
Wait, aren't the specifier ID numbers only 4 bytes?
Yes, indeed, these numbers are 32-bit and could easily be stored in 4 bytes as integers. But for disbursement IDs, the program expects a string, and we're trying to not change the program. And since the largest 32-bit integer is 2,147,483,647 (or unsigned 4,294,967,295), each integer ID has the possibility of being 10 bytes long! Two of those and we're already at the limit, given the challenge ID is delimited by a byte (the colon, :).
But the fact they're numbers does open a new possibility: can we encode these numbers differently? In theory, we can still store them in 4 bytes, just as whatever those characters map to, no?
Yes, that's true! But it would make for some really unintelligible strings and that seems dangerous. However, we already have a system for encoding/decoding numeric IDs in our system: Hashids! (Note: Now known as Sqids).
Time to double check the math and understand our limits:
- The largest possible integer ID (given they're 32-bit unsigned integers) is 4,294,967,295
- Hashids are longer the larger the integer you're encoding
- 4,294,967,295 Hashid encoded is
J450W1Zwith our salt, so 7 bytes
Now, saving 3 bytes might not seem like a lot, but it's actually a whopping 30% reduction - Two encoded numbers would be 14 bytes, which leaves room for 7 more bytes for the challenge ID and separators, which we could make as small as possible.
Not only would this get us way below the max disbursement ID length of 21, it would match our existing APIs and all other client-facing SDKs in using Hashids, a win-win!
Migrating the challenges
The path was clear:
- Migrate all challenges to have max 1 or 2 character challenge IDs
- Migrate all challenges to use Hashids instead of numeric IDs in challenge specifiers (also remove the
=>in favor of a single character:)
I sanity checked this migration by converting the longest 1000 disbursement IDs for each of the longer four challenge types (referrals, verified referrals, $AUDIO match buyer, $AUDIO match seller) and taking the max length. The max of all four was 18 bytes.

The Hardest Problems in Computer Science
"There are 2 hard problems in computer science: cache invalidation, naming things, and off-by-1 errors. - Leon Brambrick" - Jeff Atwood
Even after all this, there was still another error! Somehow even with all the remaining submissions and the evaluate in a single transaction, we still saw "Not enough signers" for some of the challenges on my account that had failed to claim before the changes.
It was due to a pesky off-by-one error of all things!
When decoding the account that holds the attestations, the code only looked for and decoded three attestations instead of four! D'oh! Everything worked locally because locally the Reward Manager was configured to only require two attestations from Discovery Nodes (to minimize the infrastructure you needed to run while developing). And everything mostly worked in production since the happy path would return an empty account, so the client would submit all four attestations and disburse the reward.
But in the case where all four attestations submitted successfully, but the evaluate transaction failed, four attestations would remain in the program account. Then, on retry, the client would decode the account and since it only decoded three of the four, it would think only three attestations submitted successfully. Then, it would submit a new attestation, triggering the program code that clears all the submissions, and then try to disburse and fail due to "Not enough signers."
This off-by-one bug could also be the source of the "Repeated Sender" errors. The new attestation that the client tries to submit might match the one account that it neglected to decode, so it might try submitting an attestation from a node that had already attested.
It's entirely possible that this was the larger root cause of the earlier symptoms, not RPC desync. D'oh! All that extra work…
However, these efforts to get everything in a single transaction are not in vain! With four times fewer transactions, there's four times fewer failure points. In fact, this off-by-one error wouldn't even be an issue in a single transaction flow, because all attestations are submitted at once and the whole claim succeeds or fails as a single unit of work, preventing this class of bug entirely.
Rolling out the changes
One of the hardest parts of these changes is rolling them out and migrating everyone without breaking existing clients. With web clients, it's fairly trivial to make sure they're up to date, as a simple reload gets them there. With mobile… it's not quite so simple. Even with tools like Code Push, getting users on the latest and greatest remains a pain.
Like most apps, we've implemented the ability to force users to upgrade to a certain minimum version for breaking changes and keeping users up to date. We don't like to use it without giving time for users to get the updates naturally first, so as not to disrupt them.
The first step then is to update the UI to account for the new challenge IDs and specifiers while still supporting the old ones, and then let that change get adopted naturally for a while. Then, we'll force upgrade everyone to the minimum version that has support for the new challenge IDs, after it's had time to be adopted. Finally, we'll update discovery node service providers with changes to migrate their challenges to the new IDs and specifiers for the network of node operators to adopt and enforce.
Migration Pains
Bad news struck in the migration path. It turns out our SQL function implementation of Hashids is quite slow. After attempting to run the migration on a clone of the production data, we found it was prohibitively slow despite a number of different query optimizations. However, other encodings that were built-ins to Postgresql such as to_hex() were extremely fast in comparison. So we pivoted away from using Hashids and used hexadecimal instead.
Results
We rolled out these changes in September and tracked our four error categories, and the results show a resounding success:
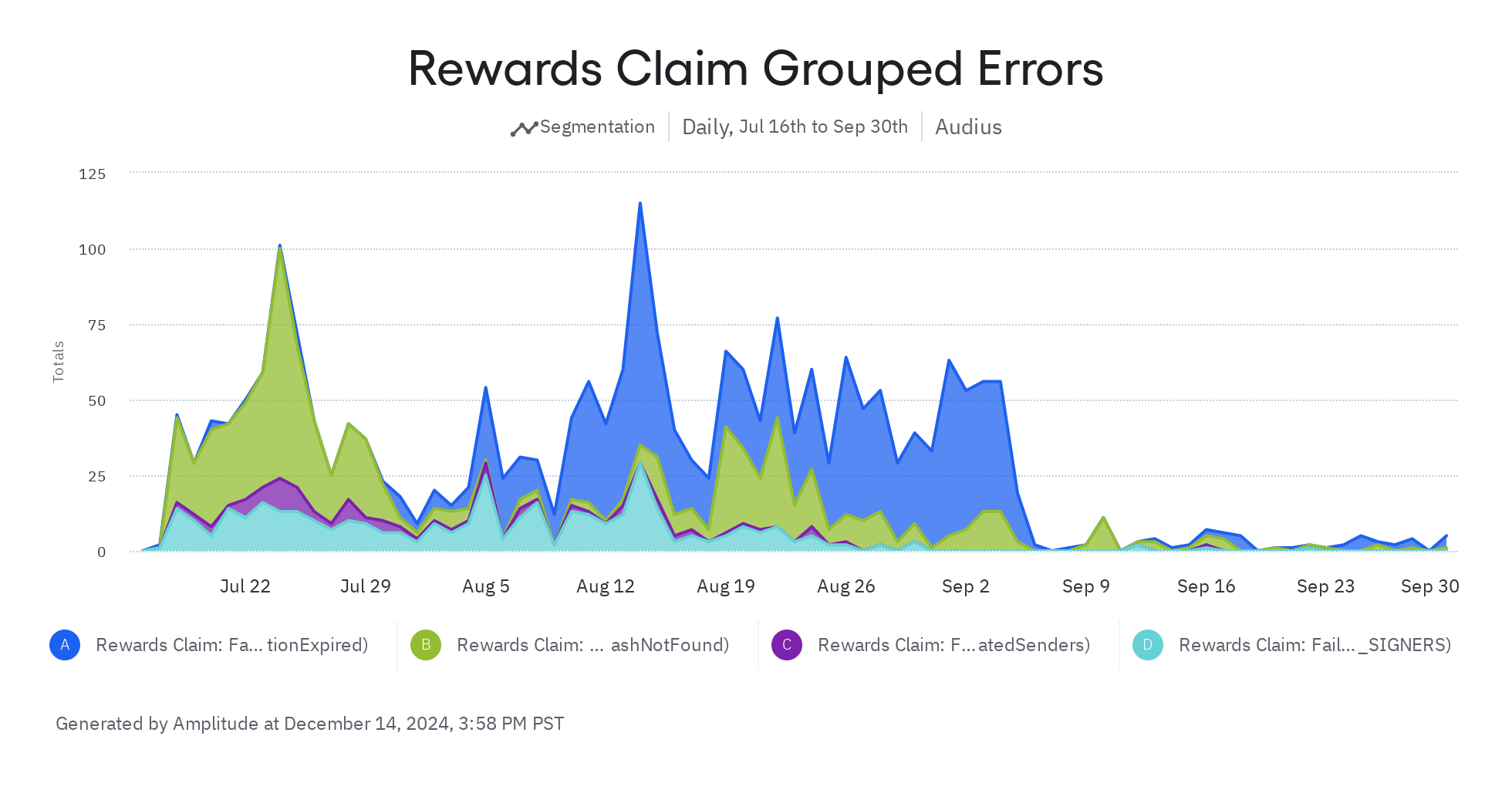
Work here is ongoing, there's much more to be done and lots of room to improve. There are still a number of ways that rewards claiming can fail. If you encounter failures, don't hesitate to reach out to [email protected]. In the meantime, we're continuing to tweak our systems to make them as resilient and reliable as possible!